Data analysis#
Learning goals
After finishing this chapter, you are expected to be able to
import SciPy and use some of its functions
create and manipulate Pandas dataframes
import data in CSV format
process this data
write data to different file formats
There are hundreds if not thousands of packages available for Python. In the final chapter of this manual, we’ll introduce some additional commonly used Python packages, in addition to NumPy and Matplotlib which you have already used. We will show how to use SciPy to perform mathematics, how to use Pandas to represent data, and how to use Seaborn to make beautiful figures.
In addition to these, there are many other packages with more specialized uses that we will not introduce here but which you’ll probably encounter during your studies. Examples include
The scikit-image package offers a lot of functionality in image analysis.
The scikit-learn package provides tools for machine learning.
The PyTorch package lets you build and train neural networks.
SciPy#
SciPy provides algorithms for many mathematical problems like optimization, integration, interpolation, eigenvalue problems, algebraic equations, differential equations, statistics and many other classes of problems. It uses NumPy arrays (which you already have used) for most of these things.
Read the docs
As always, we cannot mention all possible functionality. To grasp everything what you can do with SciPy, take a look at the documentation.
SciPy works similarly to NumPy. It is a package, and its code is organized in multiple different modules. There is a module for optimization, for differential equations, etc. To import a module, the convention is to use from scipy import <module_name>. For example
from scipy import ndimage # This import the SciPy module that lets you work with images
The ndimage module allows you to work with images. It contains many different kinds of filters (that let you change an image) and operations on images. For example, take a look at the rotate function here. It lets you rotate an image by a prespecified angle.
Exercise 9.1
Download this image file.
Load the image file using the
imageiopackage as follows
import imageio
image = imageio.imread('art.jpeg')
Show the image using Matplotlib’s
imshowfunction, give the figure a descriptive title.Rotate the image by 90 degrees using Scipy.
Visualize the rotated image using Matplotlib, give the figure a decriptive title.
Opdracht 9.1
Download dit bestand dat een plaatje bevat.
Laad het plaatje in Python met behulp van de
imageiopackage, als volgt
import imageio
image = imageio.imread('art.jpeg')
Bekijk het plaatje met Matplotlib’s
imshowfunctie (zoals in Hoofdstuk 8). Geef de figuur een goede titel.Roteer het plaatje 90 graden met behulp van Scipy.
Bekijk het geroteerde plaatje met Matplotlib. Geef de figuur weer een goede titel.
Another useful Scipy module is the integrate module that lets you numerically integrate functions in a given range. For this, we need to explain one important thing. Remember in Chapter 7 when we told you that everything in Python is an object? Well, even functions are actually objects. We can define the following function
def square(x):
return x**2
and use it like we have used functions so far, e.g.
square(4)
16
or
square(-3)
9
But we can also get the type of the function when we use its name without ( ). E.g.,
type(square)
function
and Python tells us it has type function (no surprises there). Now, if we refer to square in this way, we can also pass the function itself as an argument to other functions, and that is what happens when we use the SciPy integrate package.
For example, we can integrate our square function between \(x=0\) and \(x=4\), i.e., compute
SciPy provides multiple ways to integrate. Here, we’ll just use (an optimized version of) Gaussian quadrature.
from scipy import integrate
integrate.quad(square, 0, 4) # Use quadrature to integrate function x2 (x**2) between 0 and 4
(21.333333333333336, 2.368475785867001e-13)
Take a look a the function call and what is returned. The first return value is the result of the integral, the second the absolute error. We can verify that the answer is approximately correct by analytically computing the integral as
Exercise 9.2
Consider the function \(y=\sin(x)\).
Plot this function between \(x=0\) and \(=\pi\).
Compute the integral between \(x=0\) and \(x=\pi\) using Scipy.
Verify that the answer is correct by computing the analytical gradient.
Opdracht 9.2
Gegeven de functie \(y=\sin(x)\).
Plot de functie tussen \(x=0\) en \(x=\pi\) met behulp van Matplotlib.
Integreer de functie tussen \(x=0\) en \(x=\pi\) met Scipy.
Ga na dat het antwoord dat je krijgt klopt door zelf de integraal te berekenen.
Pandas#
The second library that we’ll look into is the Pandas package. Pandas is a very popular library that lets you work with large tables or data files, which it represents as DataFrames. A DataFrame is used to store tabular data: data that has rows (from top to bottom) and columns (from left to right). This data can be diverse. Note that Pandas does not support data structures with more than two dimensions. An important difference between NumPy arrays and Pandas dataframes is that arrays have one data type (dtype) per array, while dataframes have one dtype per column. This makes them more versatile. Moreover, we can give labels to columns, which makes it easier to understand what exactly is in the DataFrame, and avoids mixing up of columns.
The image below shows an example DataFrame. The DataFrame has five rows and five columns. Each row has an index label, which can be used to identify the row. Each column has a column label. In each column, there is one data type: the Name column contains strings, the Age column contains integers, the Marks column contains floating point numbers, the Grade and Hobby columns contain strings.
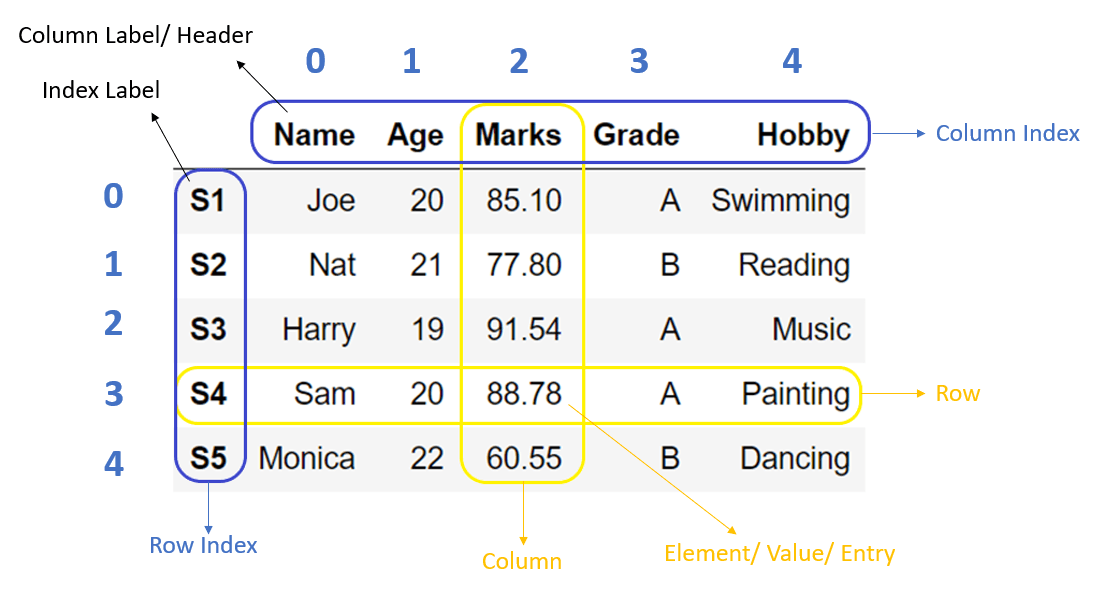
Series
Pandas also contains the Series class, which is similar to a DataFrame but only supports 1D arrays. Because DataFrames are much more commonly used, we will here focus on DataFrames.
Just like other packages, Pandas needs to be imported into Python. We import Pandas as follows. Here, pd is an alias for the pandas package name that is widely used (just like np is short for numpy).
import pandas as pd
To create a new DataFrame, we call its constructor (as you have learned in Chapter 7). The DataFrame constructor has three commonly used arguments:
pd.DataFrame(data=None, index=None, columns=None)
data: Here, you can use most of the data structures that you have seen so far: lists, NumPy arrays, dictionaries. For example, if we here provide a 2D NumPy array, columns in the DataFrame will correspond to columns in the array, and rows will correspond to rows (see example below).index: This defines how rows should be indexed. By default, this is just \(0, 1, 2, \ldots, n_{rows}-1\).columns: This defined how columns should be labeled. You can here provide, e.g., a list of strings. By default, this is just \(0, 1, 2, \ldots, n_{columns}-1\).
As you can understand, there are many ways to construct a new DataFrame object. For example, we can initialize an object based on a NumPy array:
import numpy as np
data = np.random.randint(0, 8, (5, 4)) # Create a random NumPy array
df = pd.DataFrame(data, columns=['A', 'B', 'C', 'D']) # Create a DataFrame based on the array, where column labels are A, B, C, D
print(df)
A B C D
0 7 2 2 4
1 1 0 3 2
2 2 3 3 6
3 4 3 2 3
4 6 2 5 6
We can also provide row indices using the index parameter:
df = pd.DataFrame(data, index=['Row 1', 'Row 2', 'Row 3', 'Row 4', 'Row 5'], columns=['A', 'B', 'C', 'D'])
print(df)
A B C D
Row 1 7 2 2 4
Row 2 1 0 3 2
Row 3 2 3 3 6
Row 4 4 3 2 3
Row 5 6 2 5 6
We can also initialize a DataFrame using a dictionary. The dictionary keys will then be used as column labels, and the dictionary values will be used to fill the columns. For example, the code below creates a DataFrame that contains names and ages. To initialize the dataframe, we provide a dictionary where the keys correspond to the column name and the values to the values in the column.
import numpy as np
names = ['Mila', 'Mette', 'Tycho', 'Mike', 'Valentijn',
'Fay', 'Phileine', 'Sem', 'Selena', 'Dion'] # Make a list of names
ages = np.random.randint(18, 80, len(names)) # Make a list of ages
df = pd.DataFrame(data={'Names': names, 'Ages': ages}) # Initialize a DataFrame with columns 'Names' and 'Ages'
Inspecting a Pandas DataFrame#
Pandas DataFrames can be very large. There are several ways to quickly check what’s in them. The head method will list only the first few rows in a dataframe, and the tail method only the last few.
df.head()
| Names | Ages | |
|---|---|---|
| 0 | Mila | 25 |
| 1 | Mette | 53 |
| 2 | Tycho | 50 |
| 3 | Mike | 42 |
| 4 | Valentijn | 76 |
df.tail()
| Names | Ages | |
|---|---|---|
| 5 | Fay | 35 |
| 6 | Phileine | 56 |
| 7 | Sem | 51 |
| 8 | Selena | 57 |
| 9 | Dion | 24 |
Optionally, you can add an index to head or tail to show only the rows up to some index, or starting at some index.
print(df.head(3))
Names Ages
0 Mila 25
1 Mette 53
2 Tycho 50
The info method provides a summary of the columns and data types (dtypes) in the DataFrame.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Names 10 non-null object
1 Ages 10 non-null int64
dtypes: int64(1), object(1)
memory usage: 288.0+ bytes
You can also use the describe method to get a description of all numerical columns including some statistics.
df.describe()
| Ages | |
|---|---|
| count | 10.000000 |
| mean | 46.900000 |
| std | 15.863655 |
| min | 24.000000 |
| 25% | 36.750000 |
| 50% | 50.500000 |
| 75% | 55.250000 |
| max | 76.000000 |
Indexing and slicing a DataFrame#
Just as in a list or a NumPy array, we can use indexing and slicing to select specific rows.
df[4:7]
| Names | Ages | |
|---|---|---|
| 4 | Valentijn | 76 |
| 5 | Fay | 35 |
| 6 | Phileine | 56 |
Similarly as in a NumPy array with advanced indexing (see Chapter 6), we can select rows that match a particular pattern. For example, to get the rows of all people older than 40 years, we can index the DataFrame with an array of booleans.
df[df['Ages']>40]
| Names | Ages | |
|---|---|---|
| 1 | Mette | 53 |
| 2 | Tycho | 50 |
| 3 | Mike | 42 |
| 4 | Valentijn | 76 |
| 6 | Phileine | 56 |
| 7 | Sem | 51 |
| 8 | Selena | 57 |
Although indexing and slicing in this way works, it is recommend that in Pandas you use the loc and iloc methods for indexing. Using loc, to select the same rows as above, we can do.
df.loc[df['Ages'] > 40]
| Names | Ages | |
|---|---|---|
| 1 | Mette | 53 |
| 2 | Tycho | 50 |
| 3 | Mike | 42 |
| 4 | Valentijn | 76 |
| 6 | Phileine | 56 |
| 7 | Sem | 51 |
| 8 | Selena | 57 |
We can also select a specific column using loc. For example, to get all the names of people younger than 40.
df.loc[df['Ages'] < 40, 'Names']
0 Mila
5 Fay
9 Dion
Name: Names, dtype: object
The iloc method works similarly, but just takes indices or ranges as inputs. For example, to get the age of the person in the fourth row, we use
df.iloc[3, 1]
42
Here, we can use all indexing and slicing tricks we have seen so far. For example, to select every the age of every third person:
df.iloc[2::3, 1]
2 50
5 35
8 57
Name: Ages, dtype: int64
Editing a Pandas DataFrame#
You can remove rows or columns by calling the drop method. Columns are removed by using their name, as in
df.drop(columns=['Ages'])
| Names | |
|---|---|
| 0 | Mila |
| 1 | Mette |
| 2 | Tycho |
| 3 | Mike |
| 4 | Valentijn |
| 5 | Fay |
| 6 | Phileine |
| 7 | Sem |
| 8 | Selena |
| 9 | Dion |
and rows can be dropped by using their index
df.drop([0, 1, 2])
| Names | Ages | |
|---|---|---|
| 3 | Mike | 42 |
| 4 | Valentijn | 76 |
| 5 | Fay | 35 |
| 6 | Phileine | 56 |
| 7 | Sem | 51 |
| 8 | Selena | 57 |
| 9 | Dion | 24 |
Here, you can also use a range to remove, e.g., every even row
df.drop(range(0, len(df), 2))
| Names | Ages | |
|---|---|---|
| 1 | Mette | 53 |
| 3 | Mike | 42 |
| 5 | Fay | 35 |
| 7 | Sem | 51 |
| 9 | Dion | 24 |
The drop function returns a new object with the rows or columns of your choosing dropped. This might be inefficient for very large DataFrames. In that case, you can use inplace=True, which drops columns and rows in-place, or in the DataFrame that the method is working on. Take a look at the following example code
df = pd.DataFrame({'Names': names, 'Ages': ages})
print('Original DataFrame')
print(df.head())
print('\nOriginal DataFrame after drop with inplace=False')
df.drop(columns=['Names'])
print(df.head())
print('\nOriginal DataFrame after drop with inplace=True')
df.drop(columns=['Names'], inplace=True)
print(df.head())
Original DataFrame
Names Ages
0 Mila 25
1 Mette 53
2 Tycho 50
3 Mike 42
4 Valentijn 76
Original DataFrame after drop with inplace=False
Names Ages
0 Mila 25
1 Mette 53
2 Tycho 50
3 Mike 42
4 Valentijn 76
Original DataFrame after drop with inplace=True
Ages
0 25
1 53
2 50
3 42
4 76
In the last case, we’ve permanently dropped the Names column from the DataFrame.
We can add rows to a dataframe using the concat function in Pandas. Make sure to set ignore_index=True so the new row will be assigned an index that matches the already existing indices in the dataframe.
names_new = ['Sebastiaan', 'Noëlle', 'Pien', 'Luke', 'Samuel', 'Jet', 'Louise', 'Noëlle', 'David', 'Abel']
ages_new = np.random.randint(18, 80, len(names_new)) # Make a list of ages
df_new = pd.DataFrame({'Names': names_new, 'Ages': ages_new})
df = pd.concat([df, df_new], ignore_index=True)
print(df)
Ages Names
0 25 NaN
1 53 NaN
2 50 NaN
3 42 NaN
4 76 NaN
5 35 NaN
6 56 NaN
7 51 NaN
8 57 NaN
9 24 NaN
10 22 Sebastiaan
11 55 Noëlle
12 42 Pien
13 43 Luke
14 74 Samuel
15 40 Jet
16 73 Louise
17 64 Noëlle
18 29 David
19 46 Abel
Another nice thing in Pandas is that we can easily define new columns. For example, in the DataFrame above, we can add a column that simply contains whether someone is over 60 or not, a column that checks whether someone is the oldest person in the group, a column that checks whether someone is celebrating a lustrum etc.
df['Senior'] = df['Ages'] > 60
df['Oldest'] = df['Ages'] == df['Ages'].max()
df['Lustrum'] = df['Ages'] % 5 == 0
print(df)
Ages Names Senior Oldest Lustrum
0 25 NaN False False True
1 53 NaN False False False
2 50 NaN False False True
3 42 NaN False False False
4 76 NaN True True False
5 35 NaN False False True
6 56 NaN False False False
7 51 NaN False False False
8 57 NaN False False False
9 24 NaN False False False
10 22 Sebastiaan False False False
11 55 Noëlle False False True
12 42 Pien False False False
13 43 Luke False False False
14 74 Samuel True False False
15 40 Jet False False True
16 73 Louise True False False
17 64 Noëlle True False False
18 29 David False False False
19 46 Abel False False False
This makes it very easy and interpretable to work with datasets.
Sorting DataFrames#
We can sort a DataFrame according to one of its colums. For example, we can sort all rows alphabetically by name
print(df.sort_values('Names'))
Ages Names Senior Oldest Lustrum
19 46 Abel False False False
18 29 David False False False
15 40 Jet False False True
16 73 Louise True False False
13 43 Luke False False False
11 55 Noëlle False False True
17 64 Noëlle True False False
12 42 Pien False False False
14 74 Samuel True False False
10 22 Sebastiaan False False False
0 25 NaN False False True
1 53 NaN False False False
2 50 NaN False False True
3 42 NaN False False False
4 76 NaN True True False
5 35 NaN False False True
6 56 NaN False False False
7 51 NaN False False False
8 57 NaN False False False
9 24 NaN False False False
or sort by age, in descending or ascending order. For example, to get the four youngest people in the list, we can use
print(df.sort_values('Ages', ascending=True)[:4])
Ages Names Senior Oldest Lustrum
10 22 Sebastiaan False False False
9 24 NaN False False False
0 25 NaN False False True
18 29 David False False False
Exercise 6.7 revisited
Consider the grades.npy file in Exercise 6.7. Using Pandas, with a few lines of Python we can address all questions in that exercise. First, we create a DataFrame
grades = np.load('grades.npy')
df = pd.DataFrame(data=grades, columns=['Exam', 'Resit'])
Then, we answer the questions as follows:
How many students are there in the class?
len(df)
How many students passed the exam the first time (grade \(\geq 5.5\))?
df['Passed'] = df['Exam'] >= 5.5 # Make a new column that says which students passed
df['Passed'].sum() # Count all True values
What was the average grade of students that passed the exam the first time?
df.loc[df['Passed'], 'Exam'].mean() # Compute the average grade of those students that passed
Not all students that failed the exam, also took the resit. How many students didn’t?
df['No show'] = df['Resit'].isna() & ~df['Passed'] # Make a new column that contains the students that didn't take the resit (isna), and didnt't pass (the ~ is short for negative)
df['No show'].sum()
In the end, the DataFrame df then looks like
Exam |
Resit |
Passed |
Failed |
No show |
|
|---|---|---|---|---|---|
0 |
3.0 |
6.2 |
False |
True |
False |
1 |
6.5 |
NaN |
True |
False |
False |
2 |
6.1 |
5.9 |
True |
False |
False |
3 |
3.9 |
5.4 |
False |
True |
False |
4 |
6.5 |
NaN |
True |
False |
False |
5 |
1.3 |
6.4 |
False |
True |
False |
6 |
7.4 |
NaN |
True |
False |
False |
7 |
8.5 |
NaN |
True |
False |
False |
8 |
1.8 |
NaN |
False |
True |
True |
9 |
5.3 |
7.2 |
False |
True |
False |
10 |
3.4 |
6.8 |
False |
True |
False |
11 |
5.5 |
6.0 |
True |
False |
False |
12 |
1.4 |
NaN |
False |
True |
True |
13 |
5.4 |
7.2 |
False |
True |
False |
14 |
4.6 |
5.0 |
False |
True |
False |
15 |
6.3 |
NaN |
True |
False |
False |
16 |
6.5 |
NaN |
True |
False |
False |
17 |
4.0 |
NaN |
False |
True |
True |
18 |
5.3 |
6.2 |
False |
True |
False |
19 |
5.4 |
5.3 |
False |
True |
False |
20 |
3.7 |
6.2 |
False |
True |
False |
21 |
1.2 |
3.4 |
False |
True |
False |
22 |
9.4 |
NaN |
True |
False |
False |
Plotting Pandas data#
Pandas allows you to directly plot data from a DataFrame in a way that seemlessly integrates with Matplotlib. For example, to make a bar plot of all ages in our example DataFrame, we can use
import matplotlib.pyplot as plt # Import matplotlib
df = pd.DataFrame({'Names': names, 'Ages': ages}) # Create dataframe
fig, ax = plt.subplots() # Create figure and axes
df.plot(x='Names', y='Ages', ax=ax, kind='bar') # Plot directly from dataframe. Note that we provide the ax object as axes.
ax.set_title('My first DataFrame plot'); # Add title
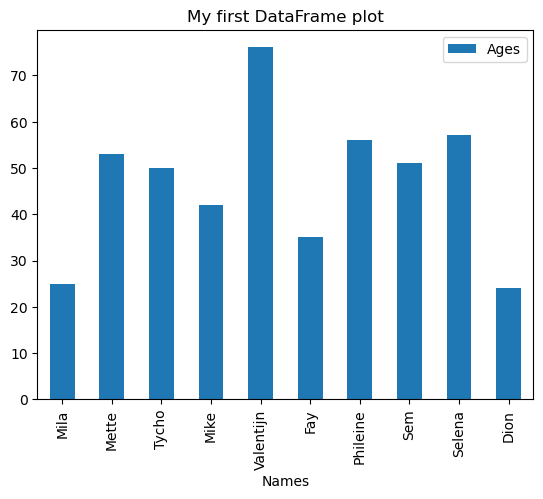
The kind argument lets you choose the kind of plot you want to make for a DataFrame. Take a look at the plot documentation to see which kinds of plots you can make.
Reading data to Pandas#
Pandas is able to read several useful file formats, the most common ones being CSV (comma-separated values) and Excel files. To read a CSV file, use read_csv.
df = pd.read_csv(<filename>)
Moreover, you can directly read Excel files using pd.read_excel. It could be that you have to install one additional package for that like openpyxl.
Exercise 9.3
Download a CSV file here.
Load this CSV file into a Pandas DataFrame.
Inspect the contents of the DataFrame using the
inspectandinfofunctions function. Look at the first few rows in the DataFrame using theheadfunction. The first column contains all last names in The Netherlands.Find out how many people in The Netherlands share your last name. Hint: Use the
locfunction.Find out what are the ten most common names in The Netherlands. Make a bar plot for the occurence of these names. Hint: Use the
sort_valuesfunction.See if you can find who among your fellow students has the most common last name.
Opdracht 9.3
Download hier een CSV bestand.
Laad dit CSV bestand in een Pandas DataFrame.
Bekijk de inhoud van het DataFrame met de
inspecteninfomethods. Bekijk de eerste paar rijen van het DataFrame met deheadfunctie.Het bestand bevat (als het goed is) alle achternamen in Nederland. Hoe vaak komt jouw achternaam voor? Hint: Gebruik de
locfunctie.Wat zijn de tien meest voorkomende achternamen in Nederland? Maak een bar plot (staafdiagram) waarin je laat zien hoe vaak deze namen voorkomen. Hint: Gebruik de
sort_valuesfunctie.Wie van je studiegenoten heeft de meest voorkomende achternaam?
Exercise 9.4
Download the CSV file here. This file shows the cost of a Big Mac over time in 57 countries over a period of twenty years, from 2000 to 2020.

Load this file into a Pandas DataFrame.
Inspect the DataFrame.
Use Matplotlib to plot the cost of a Big Mac in local currency in Denmark over time. Use the
datecolumn as your \(x\)-value. Hint Useplt.xticks(rotation=70)to rotate the time labels.The
dollar_pricecolumn shows the cost of a Big Mac in dollars, also referred to as the Big Mac Index. Find out which country has the most expensive Big Mac in 2020, and which country has the cheapest Big Mac. Hint Usenp.unique(df['name'])to get all unique country names in the DataFrame.
Opdracht 9.4
Download hier een CSV bestand. Dit bestand bevat de prijs van een Big Mac in 57 landen, in de periode van 2000 tot 2020.
Laad het bestand in een Pandas DataFrame.
Inspecteer het DataFrame om te kijken wat de kolommen betekenen.
Gebruik Matplotlib om de prijs van een Big Mac in Denemarken Deense kronen tussen 2000 en 2020 te plotten. Gebruik hiervoor de
datecolumn als \(x\)-waarde. Hint Gebruikplt.xticks(rotation=70)om alle labels op de \(x\)-as een tikje te roteren.De
dollar_pricekolom bevat de waarde van een Big Mac in dollars. Dit wordt ook wel de Big Mac-index genoemd. Bepaal welk land de duurste Big Mac had in 2020, en welk land de goedkoopste. Hint Gebruiknp.unique(df['name'])om een lijst unieke namen van landen te krijgen, en gebruik eenfor-loop om je antwoord te krijgen.
Seaborn#
Seaborn provides a high-level plotting library that works seamlessly with Matplotlib. Take a look at the Seaborn examples library to see some of the things that you can do with Seaborn. By convention, we use Seaborn with an sns alias, i.e.,
import seaborn as sns
Seaborn is the result of a perfect marriage between Matplotlib and Pandas. It naturally makes very informative figures of Pandas dataframes, and it is often sufficient to just mention which column you want to use in which role when making a figure. For example, consider the Iris dataset that you used in Chapter 8. This dataset can be loaded using the scikit-learn (or sklearn) package as below. Then, we make a DataFrame that contains that data, with the features in columns, and a column for the label of each flower.
from sklearn import datasets
iris_data = datasets.load_iris() # Directly loads the Iris dataset into a dictionary iris_data
df = pd.DataFrame(data=iris_data['data'], columns=iris_data['feature_names']) # Make a dataframe using dict
df['species'] = iris_data['target_names'][iris_data['target']] # Add a column for the target names
df.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
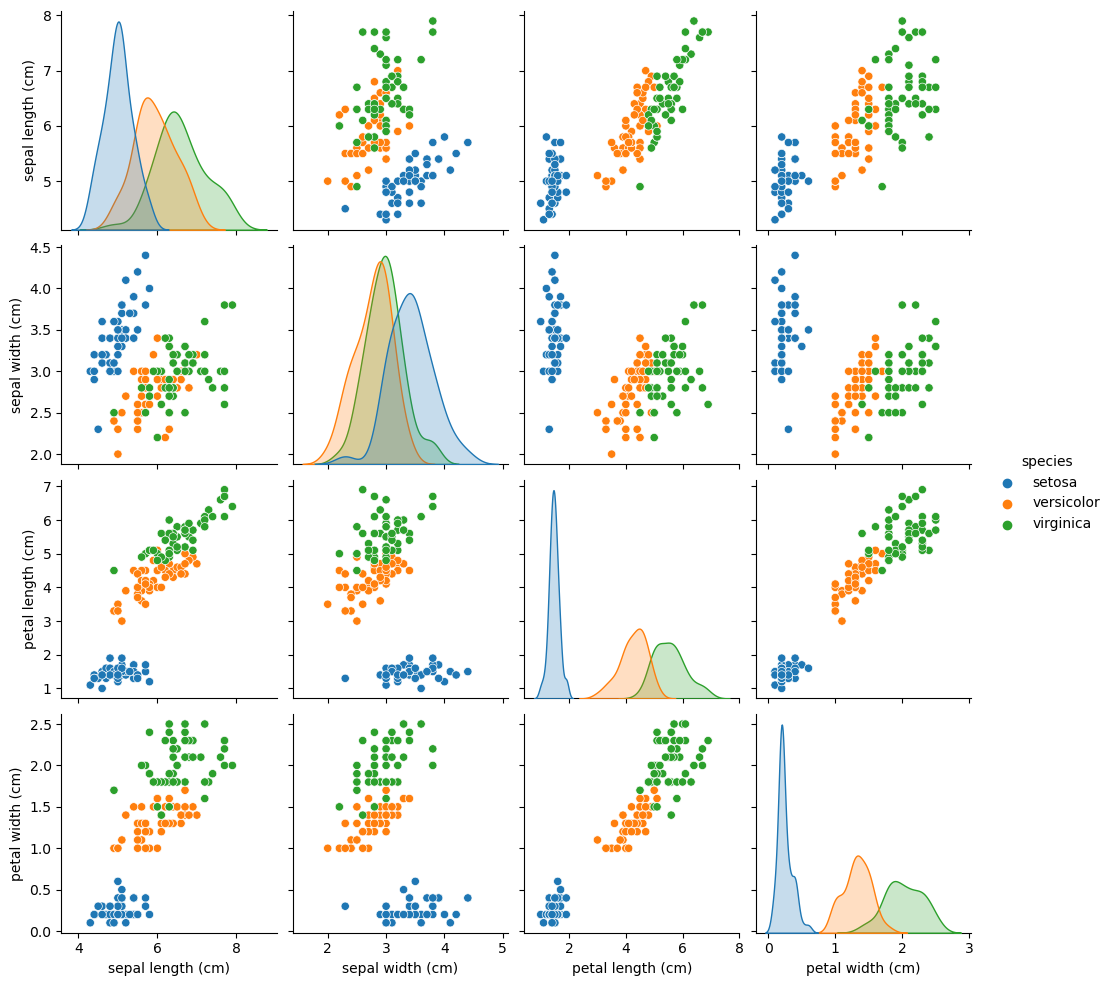
Now using Seaborn, we can - in one line - make a pairplot for this data. This pairplot contains multiple scatter plots (one for each pair of features), and histograms (one for each feature). Individual flowers/samples are color-coded according to their label. You might recognize the bottom left figure as the one you created in Exercise 8.5.
import seaborn as sns
sns.pairplot(df, hue='species');
df.describe()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
By default, Seaborn plots look quite pleasant. You can also style your plots by choosing a color palette.
Exercise 9.5
Get the
healthexpdataset from Seaborn as follows
df = sns.load_dataset('healthexp')
Inspect the data set using Pandas methods
headanddescribe. What do you see in this data set?Use the Seaborn function
lineplotto replicate the image below. Look at the documentation, and choose which values to provide tox,y, andhue.Use Matplotlib, Pandas, or Seaborn to make a bar plot of spending per life years in 2020 as below. One solution is to first make a DataFrame with only rows relating to 2020. Note: Depending on the method that you use, the resulting figure will not match exactly.
Opdracht 9.5
Maak een DataFrame op basis van de
healthexpdataset in Seaborn, als volgt
df = sns.load_dataset('healthexp')
Bekijk de data set met Pandas. Wat zie in je de dataset?
Gebruik de Seaborn functie
lineplotom zo goed mogelijk onderstaande figuur na te maken. Kies de juiste input voor parametersx,y, enhue.
4. Gebruik Matplotlib, Pandas, of Seaborn om een bar plot (staafdiagram) te maken van de uitgaven per levensjaar in 2020, zoals hieronder. Een mogelijke oplossing is om eerst alleen de data (rows) van 2020 te selecteren met
loc. Afhankelijk van de methode die je kiest zal je figuur er waarschijnlijk net wat anders uitzien, dat is niet erg.